Generating Classical music with timing
Project Motivation
If you were to ask a human to create 10 hours of music for you, it may take them weeks or months for them to complete the task. However, you could give the task task to a computer and let it run overnight and get your output the next day. As some of our team have background experience playing instruments, this project was an interesting topic to focus on. We figured that we could see how well we could get the generated music with a variety of conditions set. We planned to experiment with a number of different factors, including the composer of the piece, the number of epochs while training, and the style of the pieces used to train our model.
Throughout the course of the project, we were constantly surprised by the output of our system as it would do things we wouldn’t expect. We saw very low grade music being created at the beginning, but with some changes we were able to make the necessary modifications to improve quality. We also ran into a number of technical challenges along the way. In this blog post, we’ll detail how we did it and interpret the results of our project.
MIDI File Conversion and Pre-Processing:
We used the Music21 Python library to preprocess the midi file as well as to generate midi files from numpy arrays.
def get_notes(filename):
buffer_size = 500000
notes = [''] * buffer_size
Last_time = 0
offset = []
midi = converter.parse(filename)
print('parsing {}'.format(filename))
try: # file has instrument parts
s2 = instrument.partitionByInstrument(midi)
notes_to_parse = s2.recurse()
except: # file has notes in a flat structure
notes_to_parse = midi.flat.notesWe created a function where we passed in the name of the MIDI file we want to convert. First, we used the Music21 converter.parse() to convert the MIDI file into a Python object. Then, we checked if the file contained multiple instrument parts. For our project, we only used piano songs so the code will mostly run the except code block. If a song has multiple parts, we parse the first part (usually piano).
for element in notes_to_parse:
if isinstance(element, note.Note):
time = int(element.offset * 4)
if notes[time] == '':
notes[time] = str(element.pitch.midi)
last_time = time
elif isinstance(element, chord.Chord):
time = int(element.offset * 4)
if notes[time] == '':
notes[time] = '.'.join(str(n) for n in element.normalOrder)
last_time = time
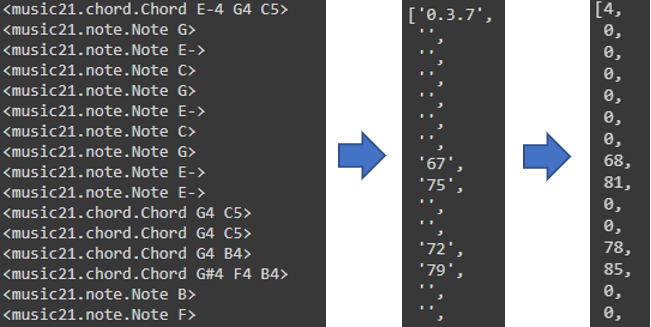
return notes[:last_time]The notes_to_parse list contains multiple properties of a Music21 Stream. A Stream contains multiple music properties such as the TimeSignature or Part. For the purposes of our project, we are only interested in Notes and Chords. We select the Notes and Chords and check the time (offset in music21) it is played. We then encode these information in a list. In midi files, each Note has a distinct midi number ranging from 21 to 108. We store each Note as string of its midi number.

We store the Chords as a string of its normal order[1]. For example a Chord of notes G,E,D will be stored as “2.3.7”. Multiple chords can have the same normal order since normal order is a way to generalize chords. The index to store that element is its offset times 4 (The offset are all multiples of 0.25). If no notes or chords were played at that time, an empty string is stored in the list.

In this function, we only convert one song into a list of strings. To use multiple songs for training, we simply appended the list into a larger list containing notes from every song. This step can be visualized by the first arrow in the below picture.
def prepare_sequences(notes, n_vocab, note_to_int):
sequence_length = 400
network_input = []
network_output = []
for i in range(0, len(notes) - sequence_length, 1):
sequence_in = notes[i:i + sequence_length]
sequence_out = notes[i + sequence_length]
network_input.append([note_to_int[char] for char in sequence_in])
network_output.append(note_to_int[sequence_out]) n_patterns = len(network_input) normalized_input = np.reshape(network_input, (n_patterns, sequence_length, 1))
normalized_input = normalized_input / float(n_vocab)
network_output = to_categorical(network_output)
return (network_input, normalized_input, network_output)
Prepare sequence takes the notes data and maps each notes to a distinct integer. It then takes the processed notes and turns it into a multi-class classification task. It chops up the notes data into continuous sequences of notes with length defined by sequence_length. It keeps the sequences as X data, and the note following the sequence as y label. It then normalizes the X data into a value between 0 and 1.
The sequence_length is a tunable parameter, by adjusting this number, we can control how much of the previous notes the current notes depends on. We found when this number is below 100 the output was not great. After few attempts, we settled using 400 as the sequence_length. Setting this number too high would be meaningless, since the LSTM cells’ memory would starts to deteriorate as the sequences becomes too long.
Then we used train_test_split from sklearn to split and shuffle the data into training and testing data. We want to train the model using a section of the songs, and test it on a different section of the songs that the model has never heard before.
Training Music Selection Process:
When selecting music, we’d like to have a defined style of piano piece that we train the Neural Net on. The desired effect would be an output that mimics the characteristics of that style of piece. For example, if all of the training data pieces are in ¾ time because that is required of pieces of the specific style, then it would be a part of our success criteria for the output to be in ¾ time. There are also other stylistic elements such as long runs up and down the piano or trills that would be emblematic of the style we are aiming for. There were a number of styles that we could have selected to focus on as our training source. Some of the top options were Nocturnes, Preludes, Sonatas, Mazurkas, and Waltzes.
After looking at what was available and the characteristics of each type, we decided to focus on Sonatas. The motivation behind this was that there were a lot of Sonatas available and they had a particular form to them. The Sonata form contains three main sections, the exposition, development, and recapitulation. In the exposition, the primary theme (which comes first) establishes the tonic note. The second theme of the exposition section is in the dominant key (which is the fifth key of the tonic scale). This transition creates harmonic tension. The development section of the Sonata is the most unstable section of the piece. It will start with the dominant key (the fifth note of the tonic scale of the piece), then venture off to other keys, then at the end of the development, return back to the dominant key. This section increases the harmonic tension. In the recapitulation section of the piece, the 1st and 2nd themes are both in the tonic key. This is because there was no tonic key themes in the development section, so the audience is subconsciously hungry for that section. Knowing what we do about Sonata form, our goal is to select pieces that would help the Neural Net hone in on these and generate music that mimicked the style.
Neural Network Design:
The Neural Network architecture heavily utilizes Long short-term memory (LSTM) cells. The recurrent neural network structure is well suited to time series data, specifically like music. We drew heavy inspiration from this article. In our case, we added a decreasing number of units to each layer, beginning with 512 and decreasing to 128, with each layer feeding into the next. The last layer is a dense layer with softmax activation which allowed the model to predict the next note. We used categorical_crossentropy as the loss function simply because we are preforming a multi-class classification task. One limitation of this design is that the model is only able to predict one key or chord at a time. One potential area for improvement would be to investigate how the model would perform if it was able to select multiple chords.
def create_network(network_input, n_vocab):
model = Sequential()
model.add(LSTM(512,input_shape=(network_input.shape[1], network_input.shape[2]), return_sequences=True))
model.add(LSTM(256, return_sequences=True))
model.add(LSTM(128))
model.add(Dense(n_vocab))
model.add(Activation('softmax'))
model.compile(loss='categorical_crossentropy', optimizer='rmsprop')
return modelMIDI file generation:
def generate_notes(model, network_input, pitchnames, n_vocab):
end = len(network_input)
start = np.random.randint(0, end)
int_to_note = dict((number, note) for number, note in enumerate(pitchnames))
pattern = network_input[start]
prediction_output = []
for note_index in range(500):
prediction_input = np.reshape(pattern, (1, len(pattern), 1))
prediction_input = prediction_input / float(n_vocab)
prediction = model.predict(prediction_input, verbose=0)
index = np.argmax(prediction)
result = int_to_note[index]
prediction_output.append(result)
pattern.append(index)
pattern = pattern[1:len(pattern)]
return prediction_outputThe model was trained with notes with 400 sequences in length, and it is tasked to predict the next note. So we select a random sequence from the testing set, and let the model predict the next note. We save the predicted output and then feed the latest 400 notes (399 from the testing set and 1 the model just predicted) and produce a new output. This process is repeated until we have an sequence of desired length.
We then take the generated array of notes and create a music21 stream object with elements in that array. Finally, we use the music21 to create the midi file from the object.
MIDI Visualization:
Once the MIDI file was generated by the Neural Network, we could download the file and listen to it. However, that was not sufficient for the analysis and presentation we wanted to create. With a visualization, we are able to press pause and see which notes are being played, the patterns they take, and the scales that are used in various sections of a song. It is also a great presentation method because it allows a viewer to see notes as they approach the keyboard in addition to just hearing the music. Such software is often used in conjunction with a physical keyboard to visualize a recording someone made of themselves playing. It is commonly seen on video sharing platforms such as YouTube. Our use for the software was slightly different, but still provided a profound effect for viewers of our video content.
To achieve the visualization of our output MIDI files, we researched various options and decided on one called “Piano VFX”. After downloading the software and configuring it, we got a basic proof of concept working in the form of a rendered video. We then started messing around with the controls to see the different things that it could do. We found out that you could add various effects to the notes once they intersect with the keyboard. You can see this in our project video. The only complaint about the MIDI visualization is that the way that it synced up with the music made the Audio output a little out of alignment. Someone notes would be closer in timing than they normally would. It may not be noticeable to someone who had never heard the raw MIDI file, but to the discerning ear, there was a slight difference in performance.
Output and Analysis:
Epoch 100 Sonatas (style of Piano Piece)
In this piece there are sections that run up and down the keyboard in the B♭ major scale. We know the scale through manual inspection of the MIDI visualization of the file, as seen below:
This style of scales is seen in other sonatas such as Sonata №13 B♭ major, KV 333 (1783), Movement 1 by Mozart, where there were major runs in numerous parts of the piece. Another key aspect that tells us that this piece was trained on sonatas and takes after the same format is that at times the right hand may be doing a lot then the left hand has singular pick up notes which are interleaved with a continued motif in the right hand. This is seen in this piece between 0:17 and 0:24, as is shown in the visualization below:
We see this same style in a human created sonata such as Beethoven’s Sonata №11 B♭ major, Opus 22 (1800), Movement 4 from around 0:51–0:55. Another characteristic that this piece has which is not seen in all types of pieces, but is certainly representative of the majority of sonatas is that it sounds very “clean”. This is somewhat of an intangible, but can be attributed to the use of major scales as opposed to minor scales. In this generated work, the key begins in B♭ major. In numerous occasions throughout the piece, we see that it deviates from scale and includes notes such as E♮ which are not included in the B♭ major scale. This goes to build harmonic tension throughout the piece which is resolved at the end of the piece. This is a stylistic hallmark of the sonata form.
Underfitting results:
There are multiple instances of sequences of notes that matches Sonata used in the training set. When training with a more diverse dataset or with fewer epochs, we obtained some result that are underfitting.
This above music was generate by a model after 50 epochs of training. It plays a note repeatedly for some times before playing another note repeatedly.
This song plays a simple melody in the beginning, but shortly after, it is stuck playing the same melody repeatedly.
Other results:
The new feature of our project is that it can play notes on quarter beats or half beats. This follow example showcase our model’s new feature.
In the first half, the model plays notes very quickly, almost all notes are played on a quarter beat. But later it slows down and played notes every half beat. This example also seems to be overfitting on the training data. It is pretty difficult for us to tell if the result is overfitting since it requires us to listen and remember each of the training songs.
Conclusion:
Summary
We drew ideas and inspirations from the other articles that generated music using machine learning. However, we encoded the information of time into our data during the preprocessing step. The inclusion of time made our model possible to play notes on a quarter beat or a half beat. This made our music sounds very fast at some part while slow at other parts.
Creativity vs. Quality:
In many songs we generated, we believe the songs are “too good”. Comparing our music to other AI generated music, our result are much better. We believe the model that generated these songs might learned too much from the composer. We think it is a trade off between our model not learning enough from the training data and learning too much. In the latter case, the model starts to lose originality and would just plagiarize from the training data.
Future work & improvements:
There are many improvements that can be made to this project. The neural network structure is very simple. It does not include much regularization, and we saw some overfitting in the above example. Also, more complex architecture can be used. Cells other than LSTM, such as simpleRNN or GRU, can be experimented.
Our model is only capable of predicting one note/chord at a given time. However, there are multiple instances where more than one note/chord are played together. Maybe a different method of preprocessing and encode those pattern can lead to a model predicting more than one note/chord at any time.
Furthermore, each note our model produce is only played for one beat. Due to the way we preprocess the data, all information regarding the duration of a note is lost. A more complex way of preprocessing can be performed and retain those information.
Tools, Software, Frameworks:
We mainly did the preprocessing, training, and music generation through google Colab. We used the sequential model and LSTM layer from Keras. We relied on numpy and music21 for preprocessing and music generation.
Here is the GitHub repository containing the python notebook used to train and generate music.
References:
- “Normal Order”, Open Music Theory. [Online]. Available: http://openmusictheory.com/normalOrder.html. [Accessed May 5, 2021].
- https://viva.pressbooks.pub/openmusictheory/chapter/normal-order/
- https://newt.phys.unsw.edu.au/jw/notes.html
- music21: a Toolkit for Computer-Aided Musicology (mit.edu)
- cuthbertLab/music21: music21 is a Toolkit for Computational Musicology (github.com)
- https://medium.com/analytics-vidhya/convert-midi-file-to-numpy-array-in-python-7d00531890c
- https://towardsdatascience.com/how-to-generate-music-using-a-lstm-neural-network-in-keras-68786834d4c5